Use Textblob to Do the Sentiment Analysis Yelp Reviews
Sentiment assay for Yelp review classification

Tongue processing (or NLP) serves numerous use cases when dealing with text or unstructured text data.
Imagine if yous worked for Google News and wanted to group news articles by topic. Or imagine if you worked at a legal firm and had to find documents relevant to a particular case. Information technology would be very tiring and fourth dimension-consuming to manually sift through thousands of articles, right? This is where NLP could come in handy.
Today, let's build a simple text classifier using Python's Pandas, NLTK and Scikit-learn libraries. Our goal is to build a sentiment analysis model that predicts whether a user liked a local business or non, based on their review on Yelp.
The dataset
Our data contains 10,000 reviews, with the post-obit information for each ane:
- business_id (ID of the business being reviewed)
- date (Mean solar day the review was posted)
- review_id (ID for the posted review)
- stars (1–v rating for the business)
- text (Review text)
- type (Type of text)
- user_id (User'southward id)
- {cool / useful / funny} (Comments on the review, given past other users)
Let's see how we can go about analysing this dataset using Pandas, NLTK, and Scikit-acquire.
Importing the dataset
Firstly, let's import the necessary Python libraries. NLTK is pretty much the standard library in Python library for text processing, which has many useful features. Today, we will but use NLTK for stopword removal.
import pandas every bit pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns import nltk
from nltk.corpus import stopwords
Side by side, we can import the Yelp Reviews CSV file and shop it in a Pandas dataframe chosen yelp.
yelp = pd.read_csv('yelp.csv') Allow's get some bones information virtually the information. The .shape method tells us the number of rows and columns in the dataframe.
yelp.shape Output: (10000, x)
Nosotros can learn more than using .head(), .info(), and .describe().
yelp.head() 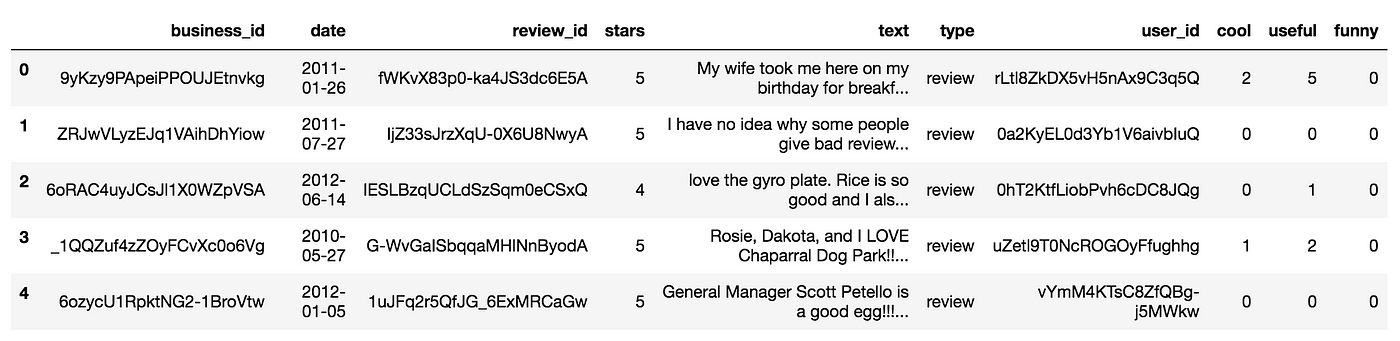
yelp.info() 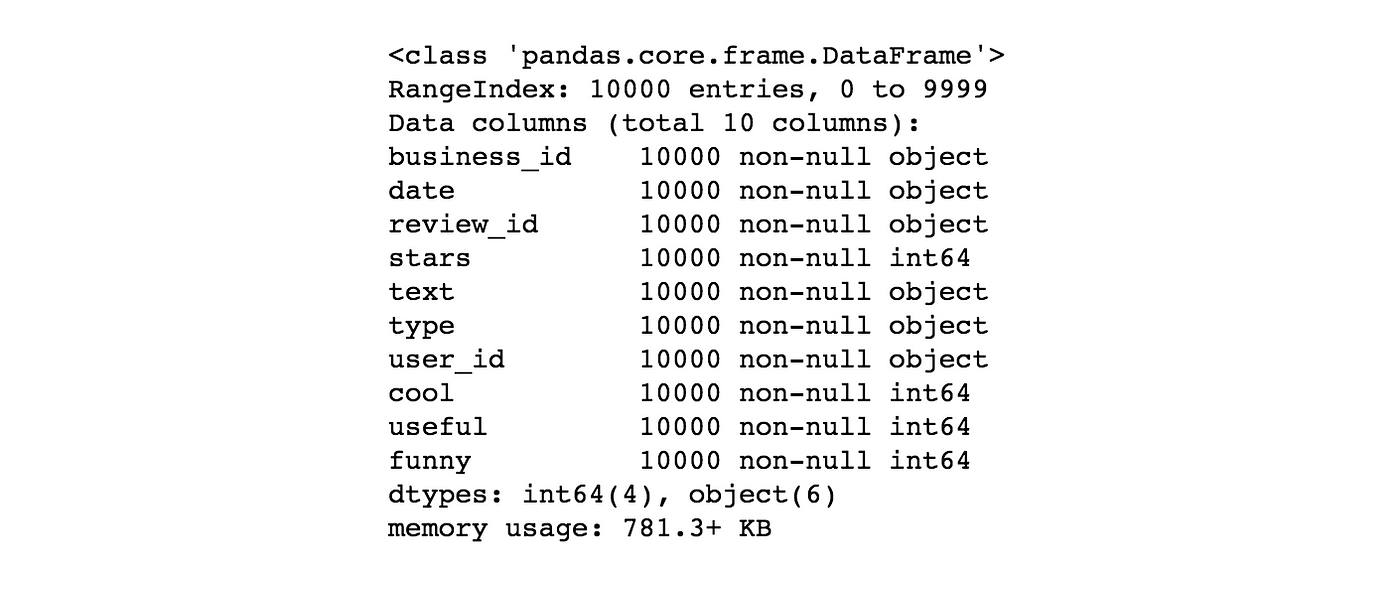
yelp.describe() 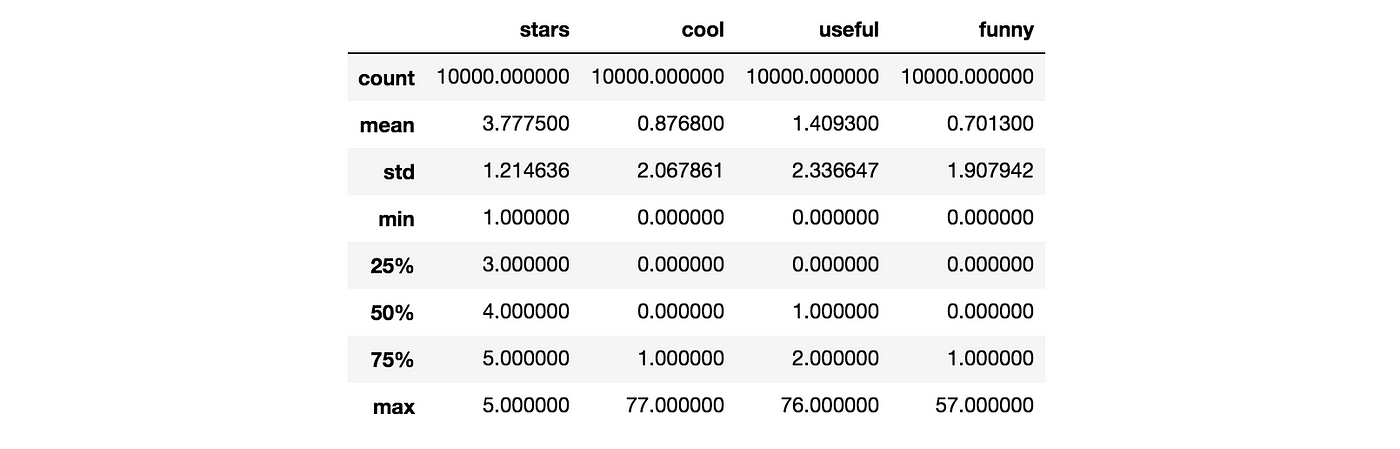
To get an insight on the length of each review, we can create a new column in yelp chosen text length. This column volition shop the number of characters in each review.
yelp['text length'] = yelp['text'].utilize(len)
yelp.head() We can now run into the text length column in our dataframe using .head():
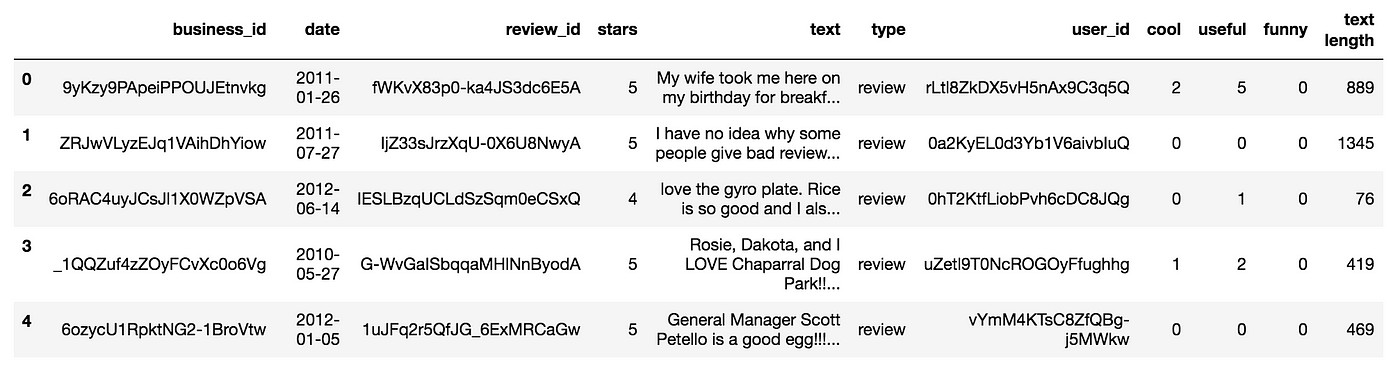
Exploring the dataset
Let'due south visualise the information a piffling more than by plotting some graphs with the Seabornlibrary.
Seaborn's FacetGrid allows the states to create a grid of histograms placed side by side. We tin can utilize FacetGrid to see if at that place'south whatever human relationship between our newly created text length characteristic and the stars rating.
k = sns.FacetGrid(information=yelp, col='stars')
thousand.map(plt.hist, 'text length', bins=50) 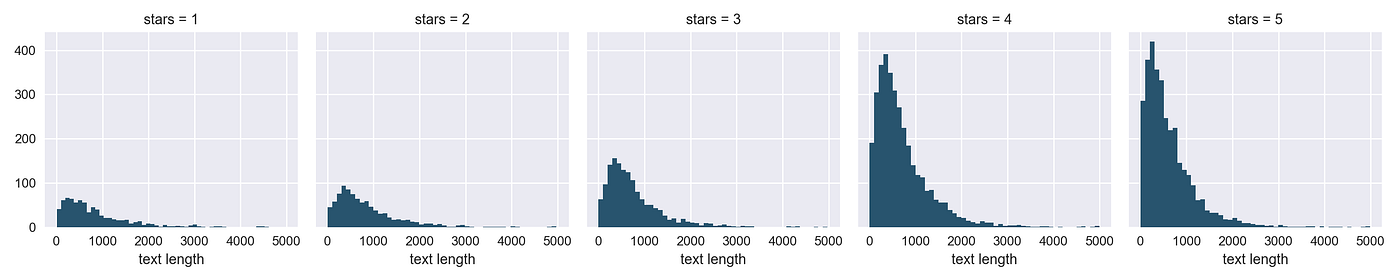
Seems similar overall, the distribution of text length is similar beyond all v ratings. Withal, the number of text reviews seems to be skewed a lot higher towards the 4-star and 5-star ratings. This may cause some issues later on in the process.
Next, let's create a box plot of the text length for each star rating.
sns.boxplot(ten='stars', y='text length', information=yelp) 
From the plot, looks like the one-star and 2-star ratings take much longer text, simply there are many outliers (which can be seen equally points above the boxes). Because of this, maybe text length won't be such a useful feature to consider after all.
Allow's group the information by the star rating, and run across if we tin find a correlation between features such as cool, useful, and funny. We can use the .corr()method from Pandas to find any correlations in the dataframe.
stars = yelp.groupby('stars').hateful()
stars.corr() 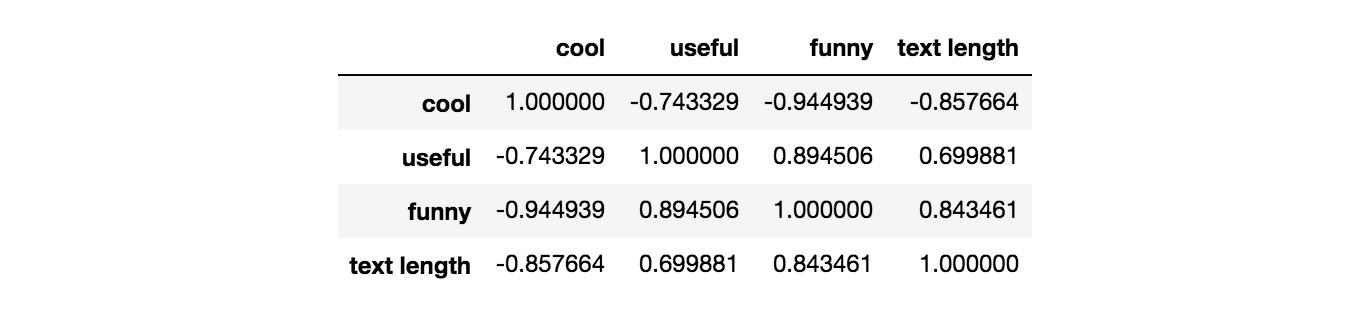
To visualise these correlations, nosotros can utilize Seaborn's heatmap:
sns.heatmap(data=stars.corr(), annot=True) 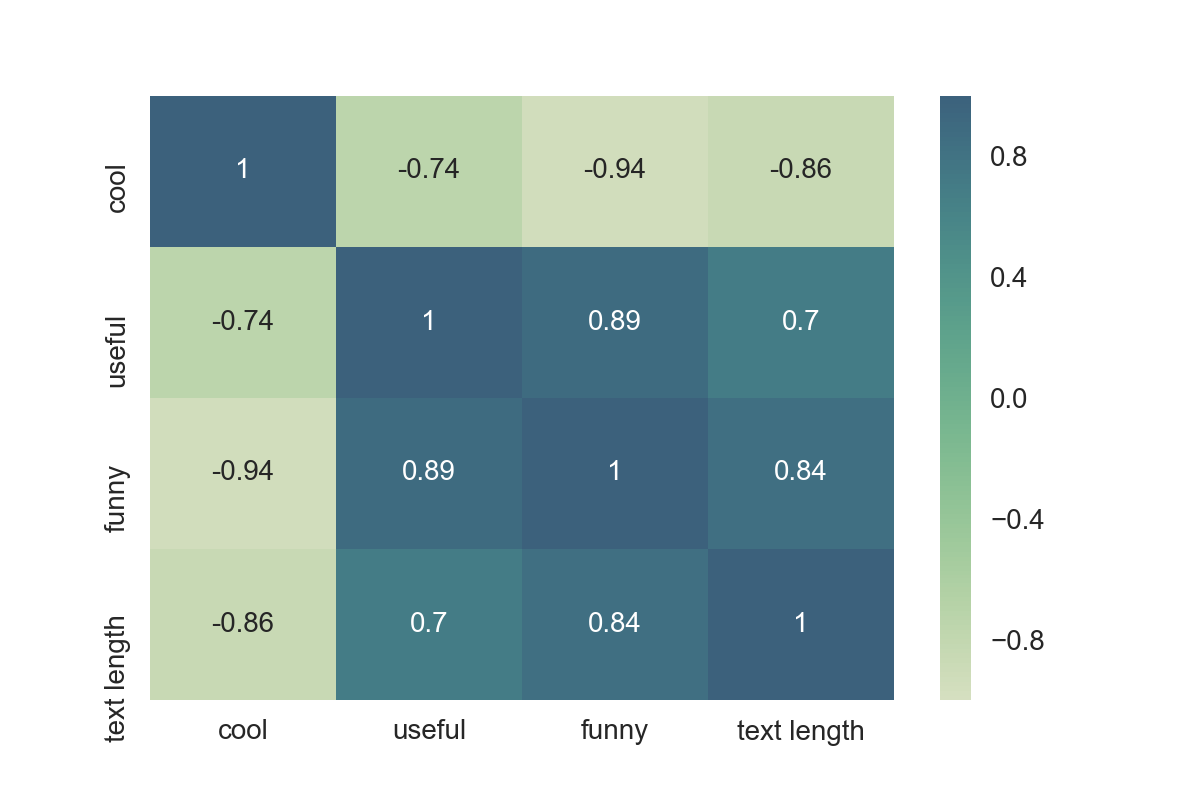
cool, useful, funny, and text length. Looking at the map, funny is strongly correlated with useful, and usefulseems strongly correlated with text length. Nosotros tin can also see a negative correlation between absurd and the other three features.
Independent and dependent variables
Our task is to predict if a review is either bad or good, so let'southward just catch reviews that are either one or 5 stars from the yelp dataframe. Nosotros tin can store the resulting reviews in a new dataframe called yelp_class.
yelp_class = yelp[(yelp['stars'] == one) | (yelp['stars'] == five)]
yelp_class.shape Output: (4086, 11)
We can run across from .shape that yelp_class only has 4086 reviews, compared to the 10,000 reviews in the original dataset. This is because nosotros aren't taking into business relationship the reviews rated 2, 3, and 4 stars.
Side by side, let's create the 10 and y for our classification task. 10 will be the text column of yelp_class, and y will be the stars column.
X = yelp_class['text']
y = yelp_class['stars'] Text pre-processing
The main issue with our data is that it is all in plain-text format.
X[0] Output: 'My wife took me here on my birthday for breakfast and it was first-class. The weather was perfect which made sitting exterior overlooking their grounds an absolute pleasance. Our waitress was excellent and our food arrived quickly on the semi-busy Sat morning time. Information technology looked like the place fills up pretty rapidly then the earlier you get here the better.\n\nDo yourself a favor and get their Bloody Mary. It was astounding and simply the best I\'ve always had. I\'thousand pretty sure they only use ingredients from their garden and blend them fresh when you guild information technology. It was amazing.\n\nWhile EVERYTHING on the menu looks excellent, I had the white truffle scrambled eggs vegetable skillet and information technology was tasty and delicious. It came with 2 pieces of their griddled bread with was astonishing and information technology admittedly made the repast consummate. It was the best "toast" I\'ve ever had.\northward\nAnyway, I can\'t wait to become back!'
The classification algorithm volition need some sort of characteristic vector in club to perform the classification task. The simplest style to convert a corpus to a vector format is the purse-of-words approach, where each unique give-and-take in a text will exist represented by ane number.
First, let's write a function that will split a message into its individual words, and return a listing. We volition also remove the very common words (such equally "the", "a", "an", etc.), too known as stopwords. To exercise this, we can have advantage of the NLTK library. The function below removes punctuation, stopwords, and returns a list of the remaining words, or tokens.
import string def text_process(text): '''
Takes in a string of text, and then performs the following:
ane. Remove all punctuation
ii. Remove all stopwords
3. Return the cleaned text every bit a list of words
''' nopunc = [char for char in text if char not in string.punctuation] nopunc = ''.join(nopunc)return [word for word in nopunc.split() if discussion.lower() non in stopwords.words('english')]
To check if the function works, allow's pass in some random text and see if it gets processed correctly.
sample_text = "Hey there! This is a sample review, which happens to contain punctuations." print(text_process(sample_text)) Output: ['Hey', 'sample', 'review', 'happens', 'contain', 'punctuations']
Seems like information technology works! At that place are no punctuations or stopwords, and the remaining words are returned to us equally a list of tokens.
Vectorisation
At the moment, we have our reviews as lists of tokens (likewise known as lemmas). To enable Scikit-learn algorithms to piece of work on our text, we need to convert each review into a vector.
Nosotros tin can use Scikit-larn'south CountVectorizer to convert the text collection into a matrix of token counts. Y'all tin imagine this resulting matrix as a 2-D matrix, where each row is a unique word, and each cavalcade is a review.
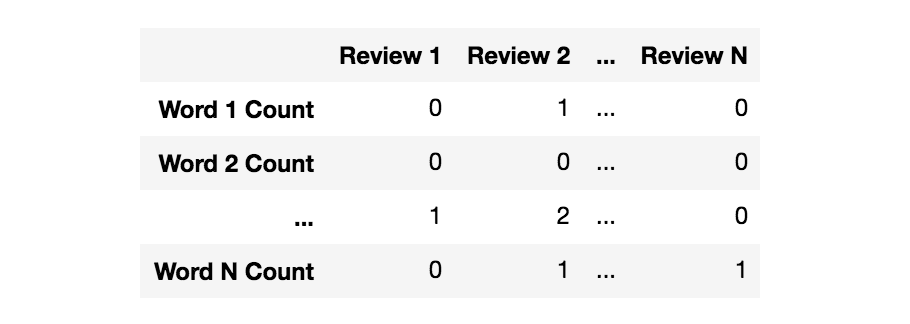
Since there are many reviews, we can expect a lot of nix counts for the presence of a word in the drove. Because of this, Scikit-larn will output a thin matrix.
Let'south import CountVectorizer and fit an example to our review text (stored in X), passing in our text_process office as the analyser.
bow_transformer = CountVectorizer(analyzer=text_process).fit(10) Now, nosotros can await at the size of the vocabulary stored in the vectoriser (based on X) like this:
len(bow_transformer.vocabulary_) Output: 26435
To illustrate how the vectoriser works, allow's try a random review and become its purse-of-word counts equally a vector. Here's the xx-5th review as plain-text:
review_25 = X[24]
review_25 Output: 'I love this place! I have been coming here for ages.
My favorites: Elsa'south Chicken sandwich, whatever of their burgers, dragon chicken wings, china's little chicken sandwich, and the hot pepper craven sandwich. The atmosphere is ever fun and the art they display is very abstract just totally cool!'
Now let'south meet our review represented as a vector:
bow_25 = bow_transformer.transform([review_25])
bow_25 Output: (0, 2099) 1
(0, 3006) i
(0, 8909) 1
(0, 9151) ane
(0, 9295) ane
(0, 9616) i
(0, 9727) 1
(0, 10847) ane
(0, 11443) three
(0, 11492) 1
(0, 11878) 1
(0, 12221) 1
(0, 13323) 1
(0, 13520) 1
(0, 14481) 1
(0, 15165) 1
(0, 16379) 1
(0, 17812) 1
(0, 17951) 1
(0, 20044) 1
(0, 20298) 1
(0, 22077) three
(0, 24797) 1
(0, 26102) 1
This means that in that location are 24 unique words in the review (after removing stopwords). Two of them appear thrice, and the rest appear only once. Let's go ahead and check which ones announced thrice:
print(bow_transformer.get_feature_names()[11443])
print(bow_transformer.get_feature_names()[22077]) Output:
chicken
sandwich
Now that we've seen how the vectorisation procedure works, nosotros can transform our Ten dataframe into a sparse matrix. To do this, let's apply the .transform()method on our bag-of-words transformed object.
X = bow_transformer.transform(X) We tin check out the shape of our new Ten.
print('Shape of Sparse Matrix: ', 10.shape)
print('Amount of Non-Zero occurrences: ', X.nnz) # Pct of not-cypher values
density = (100.0 * X.nnz / (X.shape[0] * X.shape[1]))
print('Density: {}'.format((density))) Output:
Shape of Sparse Matrix: (4086, 26435)
Amount of Not-Nil occurrences: 222391
Density: 0.2058920276658241
Training data and test data
As we have finished processing the review text in X, It'due south time to dissever our 10and y into a training and a test set using train_test_split from Scikit-learn. We will use thirty% of the dataset for testing.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.three, random_state=101)
Grooming our model
Multinomial Naive Bayes is a specialised version of Naive Bayes designed more than for text documents. Let's build a Multinomial Naive Bayes model and fit information technology to our grooming set (X_train and y_train).
from sklearn.naive_bayes import MultinomialNB nb = MultinomialNB()
nb.fit(X_train, y_train)
Testing and evaluating our model
Our model has now been trained! Information technology's time to meet how well it predicts the ratings of previously unseen reviews (reviews from the examination set). Commencement, let's store the predictions every bit a separate dataframe called preds.
preds = nb.predict(X_test) Next, let'due south evaluate our predictions against the actual ratings (stored in y_test) using confusion_matrix and classification_report from Scikit-learn.
from sklearn.metrics import confusion_matrix, classification_report print(confusion_matrix(y_test, preds))
impress('\n')
impress(classification_report(y_test, preds)) Output:
[[157 71]
[ 24 974]]
precision recall f1-score back up 1 0.87 0.69 0.77 228
5 0.93 0.98 0.95 998 avg / total 0.92 0.92 0.92 1226
Looks like our model has achieved 92% accurateness! This means that our model tin can predict whether a user liked a local business or non, based on what they typed!
Data Bias
Although our model achieved quite a high accuracy, there are some issues with bias caused by the dataset.
Let's take some singular reviews, and come across what rating our model predicts for each one.
Predicting a singular positive review
positive_review = yelp_class['text'][59]
positive_review Output: 'This restaurant is incredible, and has the best pasta carbonara and the best tiramisu I've had in my life. All the nutrient is wonderful, though. The calamari is not fried. The bread served with dinner comes right out of the oven, and the tomatoes are the freshest I've tasted outside of my mom's own garden. This is great attention to detail.\n\nI can no longer swallow at any other Italian eating place without feeling slighted. This is the first place I want take out-of-boondocks visitors I'thou looking to impress.\north\nThe owner, Jon, is helpful, friendly, and really cares about providing a positive dining experience. He's spot on with his wine recommendations, and he organizes wine tasting events which yous can find out well-nigh by joining the mailing listing or Facebook page.'
Seems like someone had the time of their life at this place, correct? We can expect our model to predict a rating of 5 for this review.
positive_review_transformed = bow_transformer.transform([positive_review]) nb.predict(positive_review_transformed)[0] Output: 5
Our model thinks this review is positive, simply as nosotros expected.
Predicting a singular negative review
negative_review = yelp_class['text'][281]
negative_review Output: 'Still quite poor both in service and food. mayhap I made a mistake and ordered Sichuan Gong Bao ji ding for what seemed like people from county commune. Unfortunately to go the skilful service U have to speak Standard mandarin/Cantonese. I practice speak a smattering just try non to utilise it equally I never feel confident about the intonation. \n\nThe dish came out with zichini and bell peppers (what!??) Where is the peanuts the dried fried red peppers and the large pieces of scallion. On pointing this out all I got was " Oh you like peanuts.. ok I will put some on" and she then proceeded to become some peanuts and sprinkle it on the chicken.\n\nWell at that point I was happy that atleast the chicken pieces were present else she would probably end up sprinkling raw craven pieces on it similar the raw peanuts she dumped on elevation of the food. \north\nWell then I spoke a few chinese words and the scowl turned into a grin and she and then became a bit more than friendlier. \n\nUnfortunately I practise not condone this type of behavior. It is all in poor taste...'
This is a slightly more than negative review. And so, we can wait our model to charge per unit this a 1-star.
negative_review_transformed = bow_transformer.transform([negative_review]) nb.predict(negative_review_transformed)[0] Output: 1
Our model is right again!
Where the model goes wrong…
another_negative_review = yelp_class['text'][140]
another_negative_review Output: 'Other than the actually great happy hour prices, its hit or miss with this place. More oft a miss. :(\n\nThe food is less than boilerplate, the drinks Non strong ( at to the lowest degree they are cheap) , simply the service is truly hitting or miss.\due north\nI'll laissez passer.'
Hither'due south another negative review. Allow's see if the model predicts this i correctly.
another_negative_review_transformed = bow_transformer.transform([another_negative_review]) nb.predict(another_negative_review_transformed)[0] Output: 5
Our model thinks this review is positive, and that'south incorrect.
Why the incorrect prediction?
1 explanation as to why this may be the example is that our initial dataset had a much higher number of v-star reviews than i-star reviews. This means that the model is more biased towards positive reviews compared to negative ones.
In conclusion, although our model was a piddling biased towards positive reviews, it was fairly accurate with its predictions, achieving an accuracy of 92% on the test set.
Source: https://urytrayudu1.medium.com/sentiment-analysis-for-yelp-review-classification-54b65c09ff7b
{kind=link}
Post a Comment for "Use Textblob to Do the Sentiment Analysis Yelp Reviews"